Focus on security education, not cyber awareness training
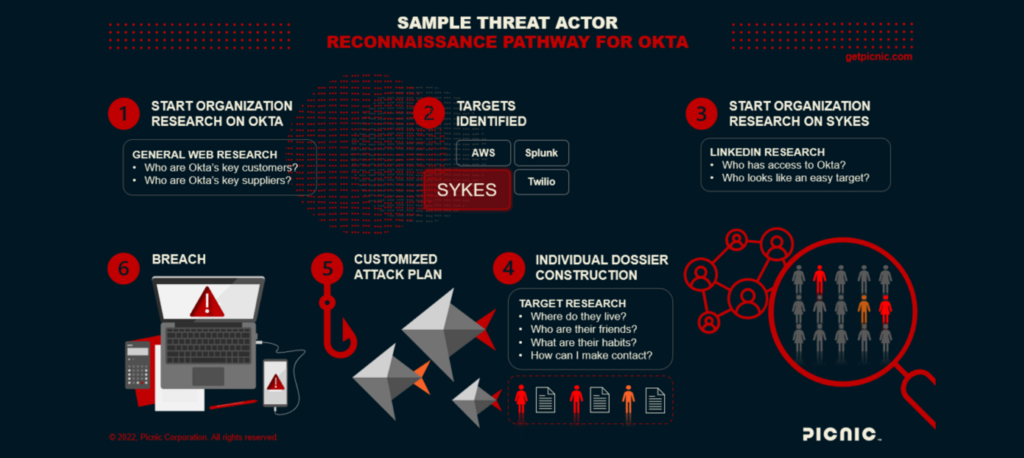
Written by Karen Walsh Phishing scams and other social engineering attacks work because cybercriminals use people’s digital footprints against them. Threat actors scrape social media and the internet, looking for
Focus on security education, not cyber awareness training Read More